Oracle AI Vector Search
Vandaag zoomen we in op een onderdeel van RAG dat we in de vorige blog niet behandeld hebben: AI Vector…
Lees meer
Zo voelde het een beetje. Op APEX World doken we een sessie in over ORACLE TEXT INDEX en werden van onze stoel geblazen. We hadden daar toch al eens van gehoord? Enkele onder ons hadden het zelfs al eens gebruikt, een hele tijd geleden. Toch waren er een aantal collega’s, veelal van de nieuwe garde, die het in Keulen hoorden donderen.
Er kwamen projecten tussen die minder met big data te maken hadden, er kwamen andere features tussen die nieuw en flitsend waren, en voor we het wisten, verloren we elkaar uit ’t oog.
Maar net zoals een niet-nader-te-noemen frituur snack supplier de vergeten frituur snack in het leven riep, houdt niets ons tegen van deze oude liefde een nieuwe boost te geven. En dat begint hier. Schreeuw het van de daken!
Oracle Text Index zit al in het Oracle-pakket sinds versie 9i, wordt standaard meegeleverd en vereist voor de meeste functionaliteiten zelfs geen extra rechten om er gebruik van te maken. Je kan het gebruiken om gebruikers snel te laten zoeken in lange teksten en documenten binnen de database, maar bijvoorbeeld ook in opgeladen bestanden en zelfs (mits een kleine rechteningreep) via url’s en bestanden op het filesystem. Oracle Text Index kan overweg met onder andere VARCHAR2, BLOB, CLOB, BFILE en XMLTYPE en dus ook externe bronnen. En het is supersnel opgezet.
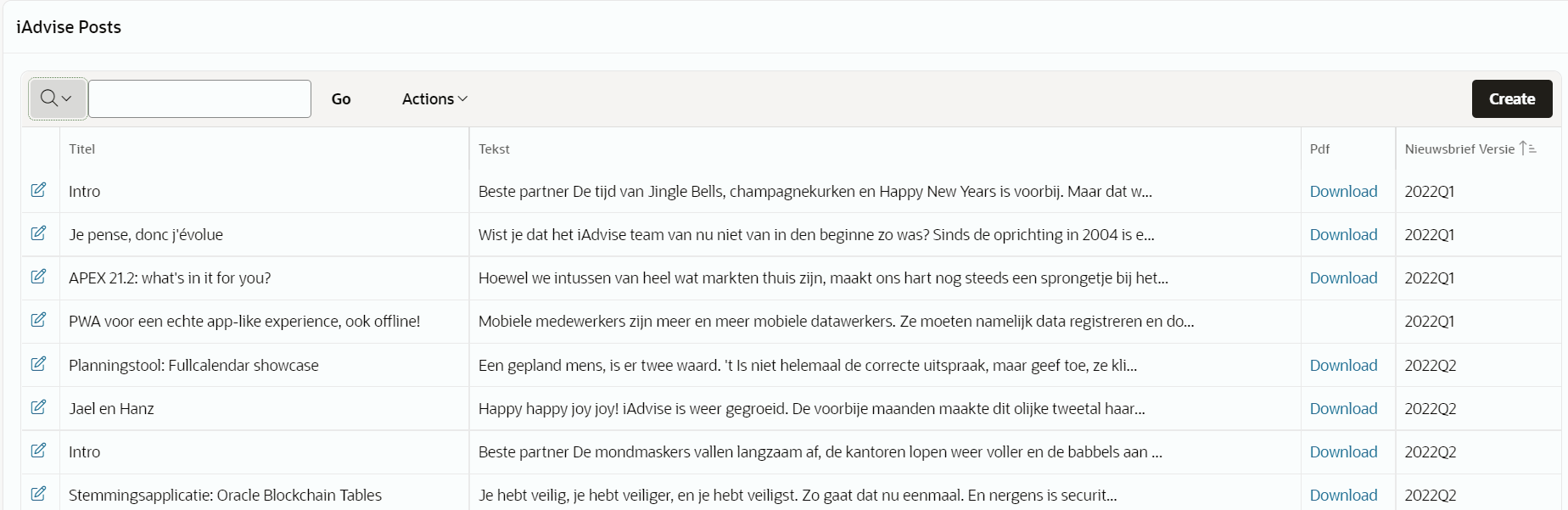
Neem nu onze eigen teskten uit de nieuwsbrief. Die zijn niet immens lang, maar lenen zich perfect om Oracle Text Index te showcasen. Alle posts zijn in een database gegoten, per artikel is de tekst op een gewone manier opgeladen en in een apart bestand.
Om zowel op de teksten zelf als op de bestanden te gaan zoeken, maken we twee indexen aan:
CTXSYS is de functie die de Oracle Text Index triggert en heeft heel wat mogelijkheden. Op dit moment houden we het op de CONTEXT-functie, die redelijk basic blijft, maar toch al heel veel klaar krijgt!
Om te zoeken binnen de index, heeft Oracle een aangepaste manier voorzien, zodat de TEXT INDEX zijn werk optimaal kan doen. De basic syntax ziet er als volgt uit:
-> select * from <<table>> where contains(<<column>>,<<value>>) > 0
Het belangrijkste van bovenstaande query is het contains-keyword, dewelke de index kan aanroepen.
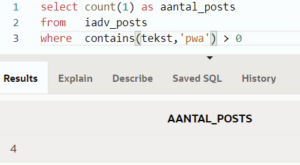
Zoeken we binnen onze nieuwsbriefposts bijvoorbeeld naar ‘pwa’, krijgen we zowel op onze tekst-kolom, als de pdf van het artikel hetzelfde resultaat.
Zoeken op tekst:
Zoeken op pdf:
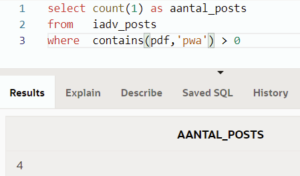
Zoals je kan zien, hebben we het wel voor PWA’s in onze nieuwsbrieven. Meer weten? Kijk even op Progressive Web Apps (PWA) zijn de toekomst
vorige voorbeeld was uiteraard basic, maar toont wel aan dat zoeken in bestanden supervlot verloopt. Binnen de CONTAINS kunnen we trouwens nog een stukje meer beginnen spelen wat betreft zoektermen. De zoekstring kan uitgebreid met heel wat combinaties, zodat je echt terugkrijgt wat je verwacht.
Enkele voorbeelden:
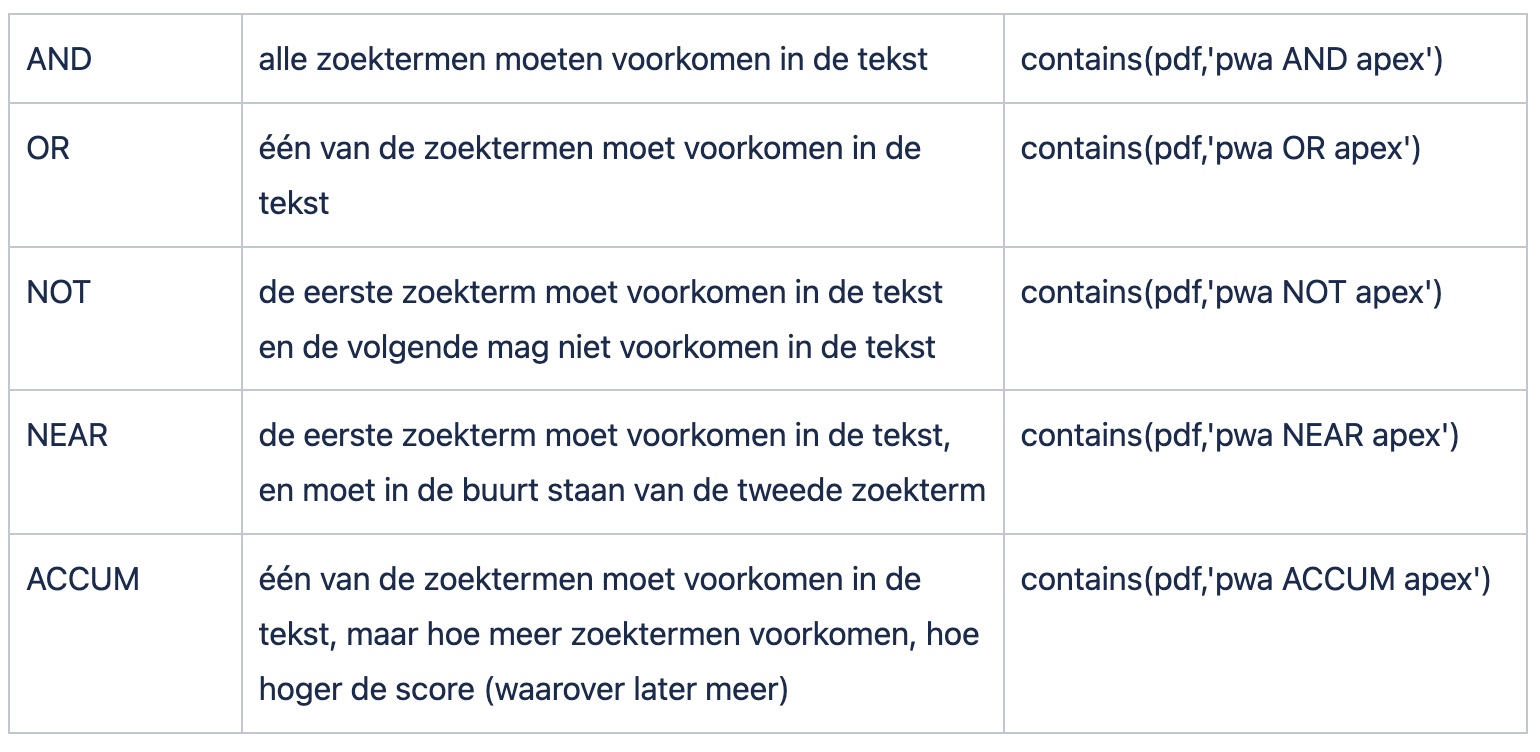
Een extra handigheid bij ORACLE TEXT INDEX is dat de zoekopdracht ook een score teruggeeft, zodat je ook nog eens op relevantie kan sorteren, indien gewenst. Scores worden op een ingenieuze manier berekend, bijvoorbeeld op het aantal keer dat het woord voorkomt in de tekst, maar ook of het woord aan het begin of op het eind van de tekst staat. En, zoals eerder aangehaald, kan ook de ACCUM-operator daar wat extra in betekenen.
-> select *, score(1) from <<table>> where contains(<<column>>,<<value>>, 1) > 0
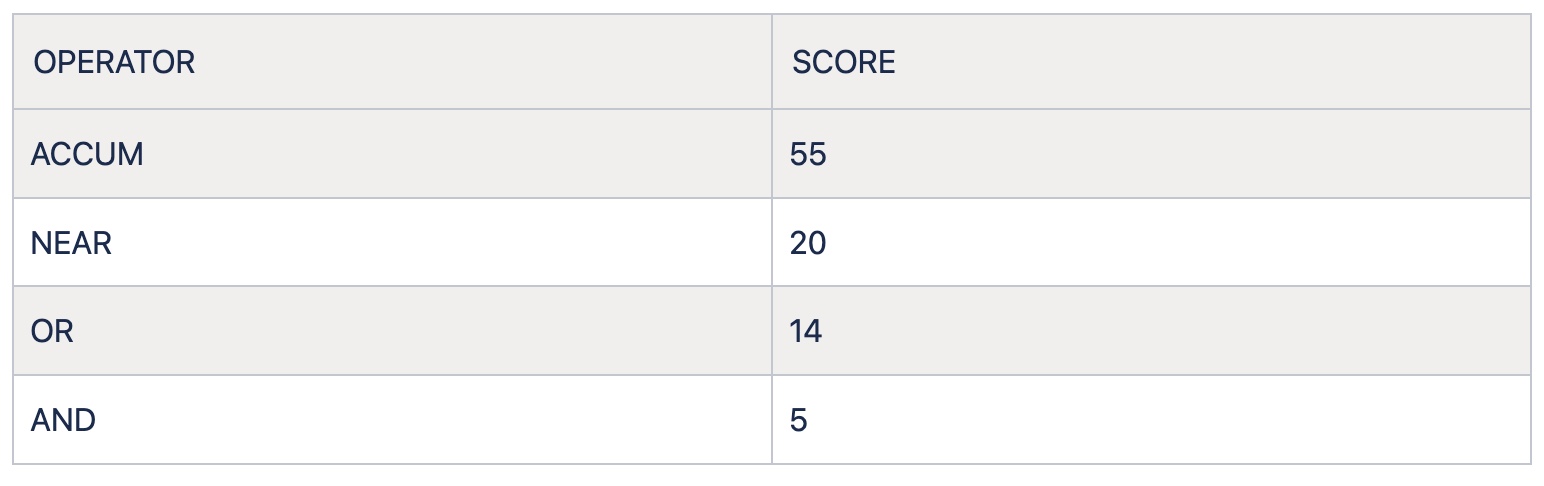
Als we kijken naar de tekst van Inspiration Day (ook te vinden elders in deze nieuwsbrief), vinden we volgende stukjes tekst terug:
Afhankelijk van de operator, krijg je een andere score:
Een laatste top-feature, is dat je zelfs niet helemaal correct hoeft te zoeken. Door gebruik te maken van Fuzzy, zal de ORACLE TEXT INDEX op zoek gaan naar termen die lijken op de zoekopdracht, maar daarom niet per sé helemaal correct zijn.
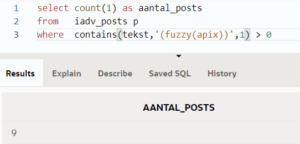
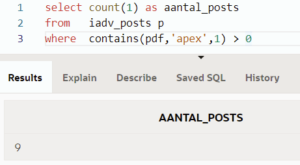
Nemen we bijvoorbeeld APEX als zoekterm, krijgen we 9 resultaten:
Met fuzzy select op de zoekterm apix, krijgen we net hetzelfde resultaat: